通过可视化训练过程,我们可以对神经网络训练更为方便的理解、调试与优化。本文将分别介绍三种主流的神经网络框架 (TensorFlow、PyTorch及Keras) 中的可视化方法。
TensorFlow训练过程可视化
Tensorboard是tensorflow内置的一个可视化工具,它通过将tensorflow程序输出的日志文件的信息可视化使得tensorflow程序的理解、调试和优化更加简单高效。 Tensorboard的可视化依赖于tensorflow程序运行输出的日志文件,因而tensorboard和tensorflow程序在不同的进程中运行。 TensorBoard给我们提供了极其方便而强大的可视化环境。它可以帮助我们理解整个神经网络的学习过程、数据的分布、性能瓶颈等等。
官方介绍:https://tensorflow.google.cn/guide/summaries_and_tensorboard
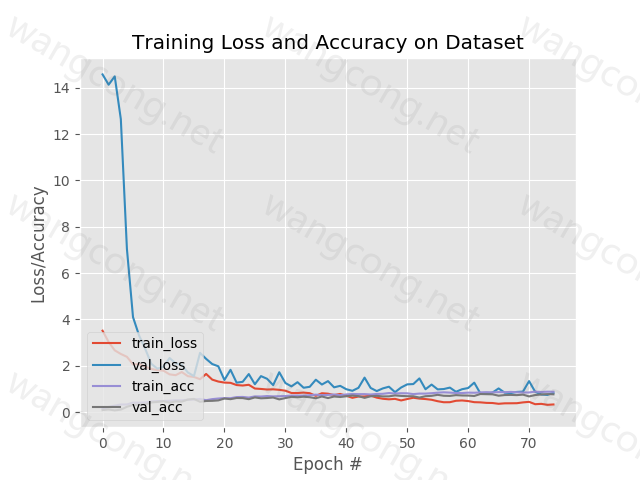
查看自己训练过程中的loss变化以及参数的变化过程,以及自己图运算的流程。
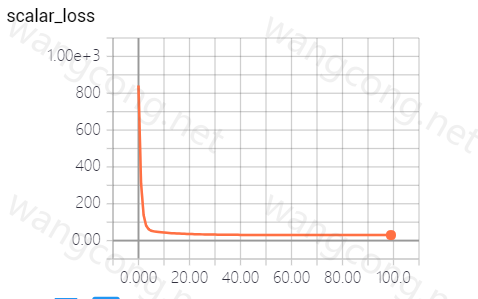
查看损失
1
2# 查看损失
tf.summary.scalar('scalar_loss', loss)![]()
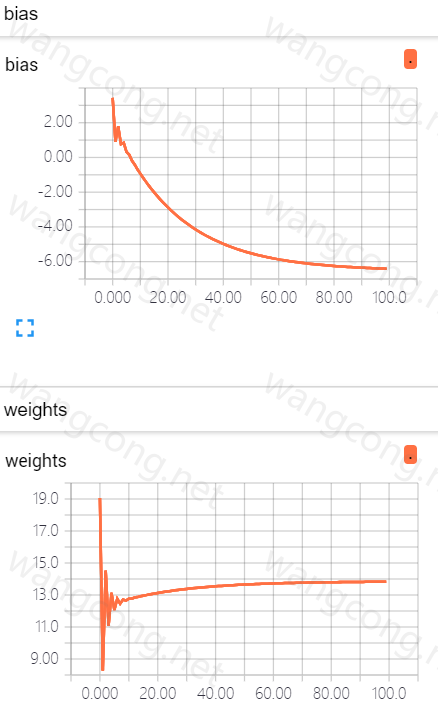
查看参数的变化
1
2tf.summary.histogram('weights',w)
tf.summary.histogram('bias',b)![]()
保存
1
2
3
4
5
6merged_summary = tf.summary.merge_all()
# 得到输出到文件的对象
writer = tf.summary.FileWriter('./result', sess.graph)
for...
summary=sess.run(merged_summary)
writer.add_summary(summary, step)命令输入
1
tensorboard --logdir ./result/
打开google浏览器,输入:http://localhost:6006
查看计算图
关于可视化的很好的总结:https://www.jianshu.com/p/bea7fc33cbf4
代码示例:
1 | # -- encoding:utf-8 -- |
PyTorch训练过程可视化
Visdom是Facebook在2017年发布的一款针对PyTorch的可视化工具。Visdom由于其功能简单,一般会被定义为服务器端的matplot,也就是说我们可以直接使用python的控制台模式进行开发并在服务器上执行,将一些可视化的数据传送到Visdom服务上,通过Visdom服务进行可视化。
官方GitHub:https://github.com/facebookresearch/visdom
PyTorch亦可使用Tensorboard进行可以可视化,GitHub上已有大神进行了实现:https://github.com/lanpa/tensorboardX
Kreas训练过程可视化
在训练文件train.py中最后加入一下代码。
1 | # Where H = model.fit_generator(...) |